
ICTSC2020予選writeup
ICTSC2020の予選にkstmで参加したので、writeupを書きます。
結果は4位でした。
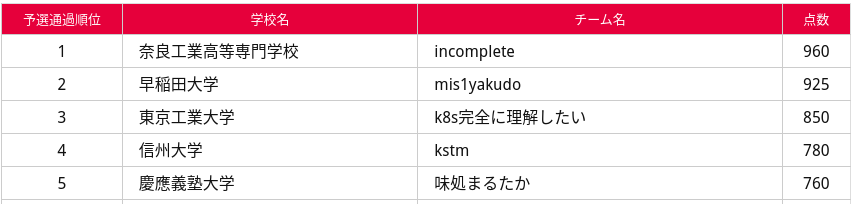
当日私が解いた問題は
- またビルド失敗しちゃった~
- ダイエットしようぜ!
- どこからもアクセスできなくなっちゃった
の3つ1でどれも満点でした
またビルド失敗しちゃった~
問題文
概要
新入社員の障害太郎くんがGoの勉強をしようとしています。
どうやらDockerのマルチステージビルドを使って、Goのバイナリをコンテナ上で実行しようとしたらうまく立ち上がらないようです。
先輩のトラシュウさんに聞いたところ、「Dockerfileが間違っている」というメモを残して業務に戻ってしまいました。
先輩のトラシュウさんの代わりに原因を特定して修正してあげてください。
前提条件
~/app/Dockerfile のみ変更可能です。
~/app/Dockerfile の1,9,12行目は変更しないでください。
ビルド用のコンテナとバイナリ実行用のコンテナは分けてください。
初期状態
~/app/Dockerfileを用いてdocker image build -t ictsc2020:0.1 .したあとに、docker run -p 80:1323 [コンテナID]をするとエラーが表示され、コンテナ上のバイナリが正常に実行できません。
終了状態
curl localhostでWelcome to ICTSC2020!が返ってくる。
また、問題の解決が永続化されている。
解説
元のDockerfileがこれです。
FROM golang:1.15.0 AS builder
ENV GO111MODULE=on
ENV GOPATH=
COPY ./server/main.go ./
RUN go mod init ictsc2020
RUN go build -o /app ./main.go
FROM alpine:3.12
COPY --from=builder /app .
EXPOSE 1323
ENTRYPOINT ["./app"]
発生しているエラーの原因が依存ライブラリが見つからないのでgoのバイナリが実行できないという物です。
これはgoのビルド時に特定のパッケージを使用していると確かglibcをdynamic linkしてビルドします。で、Docierfileに書かれているgolang:1.15.0ってイメージはdebianがベースになっているので、その上でビルドしたバイナリをalpineの環境に持っていっても動作しません。
なのでgoのビルド時にCGO_ENABLED=0って環境変数を設定すると依存ライブラリがstatic linkになるので、これを設定して他の環境でも使えるバイナリを作ることができます。
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -o /app ./main.go
ダイエットしようぜ!
問題文
概要
GoでSHA256するhash.goを書いた。これを実行するコンテナが欲しかったので雑にDockerfileを書いてビルドしてイメージを作成した。問題なくSHA256できるようになったが、イメージが大きくてテンションが上がらない。
あなたには、Dockerfileを編集したりビルドコマンドを変えたり、あるいはビルド後のイメージに対してなにかしたりしてイメージを小さくしてほしい。
ただし、hash.goのコードにはこだわっているので編集してはならない。
$ make buildでictsc-ditという名前のDocker imageを作ることができる。詳細はMakefileを参照されたい。採点の際にVMを確認する場合、どのイメージが回答によって作成されたイメージかすぐに判別できるよう、是非使ってほしい。
前提条件
hash.goを編集してはならない。
もしよければ$ make buildでDocker imageを作って欲しい。(任意)
初期状態
$ docker imagesで当該イメージを見ると796MBである。
Dockerのコマンドはsudoなしで実行できる。
終了状態
$ docker imagesで当該イメージを見ると796MBより小さくなっている
可能な限り小さくしてほしい
解説
初期状態ではgolangのイメージ上でgo runするだけのDockerfileだったので800MB近い容量がありましたね。
とりあえず秘蔵のDockerfileをコピペしてきてマルチステージビルドの導入とベースイメージをdistrolessに変更したところ、イメージは3.96MBになりました。
さすがにこれだけだと減点される気がした2のでgoのビルドオプションに -ldflags "-s -w" をつけて3.28MBまでは削減しました。
FROM golang:1.15 as builder
WORKDIR /work
COPY hash.go main.go
# Build
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 GO111MODULE=on go build -ldflags="-s -w" -a -o app main.go
# Refer to https://github.com/GoogleContainerTools/distroless for more details
FROM gcr.io/distroless/static:nonroot
WORKDIR /
COPY --from=builder /work/app .
USER nonroot:nonroot
ENTRYPOINT ["/app"]
これ以上の削減は手間がかかりそうなので時間が余ったらやろうと思ってたんですが、結果的にはそんな時間はありませんでした…
どこからもアクセスできなくなっちゃった
問題文
概要
k8sのクラスターを、マスター1台(master)、ワーカー2台(worker01, worker02)、ロードバランサー1台(lb)という構成で構築しました。
ロードバランサーにはHAProxyを用いており、kube-apiserverであるmaster(172.16.0.1:6433)へのプロキシと、各ワーカーの30080のNodePort(172.16.0.11:30080, 172.16.0.12:30080)へのロードバランシング, k8sクラスタの各ノードのデフォルトゲートウェイとしてiptablesを用いたMasqueradeを行っています。
k8sクラスタでは、nginxをreplica 数1つで展開するDeploymentと、それを外部にNodePort 30080で公開するServiceが作成されています。
このnginxに対して外部(external)からの通信においてhost01からのみアクセスできるといったアクセス制限を行うため、NetworkPolicyを用いて制限をかけたところ、host01からもアクセスできなくなってしまいました。
なぜhost01からもアクセスできないのか原因と解決方法、解決でき再起動しても問題のない作業手順を報告してください。
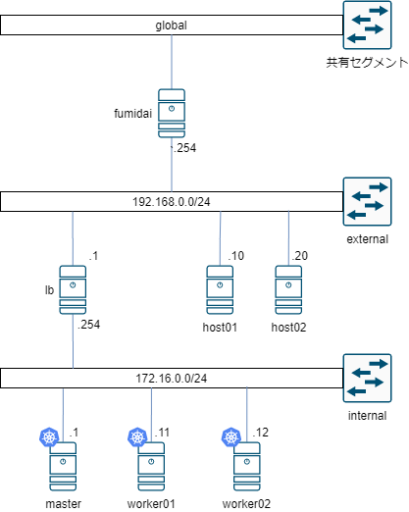
前提条件
アクセス制限はNetworkPolicyを用いること
k8sクラスターにはSSHなどでログインできない
host01の/home/user/.kube/configにkubeconfigが保存されており、kubectlコマンドでk8sクラスタを利用できる
host01の/home/user/manifestsに今回使用した各マニフェストが保存されている
初期状態
host01からcurl -m 2 192.168.0.1:30080 を実行してタイムアウトになる
host02からcurl -m 2 192.168.0.1:30080 を実行してタイムアウトになる
k8sにNamespace, Deployment, Service, NetworkPolicyが適用されている
終了状態
NetworkPolicyを利用してhost01からの通信のみを許可している
host01からcurl -m 2 192.168.0.1:30080 を実行してk8sでデプロイしたnginxのデフォルトページを表示できる
host02からcurl -m 2 192.168.0.1:30080 を実行してタイムアウトになる
終了状態が永続化されている(再起動しても上記の終了状態を確認することができる)
解説
コンテナのアクセスログにユーザのリアルIPが出てこない!!!ってやつですね、現実でもよくあります。
1. NodePortの設定
まず、NetworkPolicyをkubectl delete -fして解除してからコンテナのアクセスログを確認します。
172.20.5.0 - - [31/Oct/2020:05:01:20 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.58.0" "-"
172.16.0.12 - - [31/Oct/2020:05:01:21 +0000] "GET / HTTP/1.1" 200 612 "-" "curl/7.58.0" "-"
2020/10/31 05:06:32 [error] 28#28: *8 open() "/usr/share/nginx/html/from_host01" failed (2: No such file or directory), client: 172.20.5.0, server: localhost, request: "GET /from_host01 HTTP/1.1", host: "192.168.0.1:30080"
172.20.5.0 - - [31/Oct/2020:05:06:32 +0000] "GET /from_host01 HTTP/1.1" 404 153 "-" "curl/7.58.0" "-"
2020/10/31 05:06:52 [error] 28#28: *9 open() "/usr/share/nginx/html/from_host01" failed (2: No such file or directory), client: 172.16.0.12, server: localhost, request: "GET /from_host01 HTTP/1.1", host: "192.168.0.1:30080"
172.16.0.12 - - [31/Oct/2020:05:06:52 +0000] "GET /from_host01 HTTP/1.1" 404 153 "-" "curl/7.58.0" "-"
コンテナのログに記録されているIPは 172.20.5.0,172.16.0.12 の二種類ですね。これは2つともk8sのworkerノードに割り当てられているIPアドレスです。172.16.0.12 がworker02の外向きのinterfaceのIPで、詳しく確認していないので憶測ですが 172.20.5.0 がworker01のPod用ネットワーク側のIPアドレスだと思われます。
これはPodをk8s外に公開する時にService.NodePortを使っているからですね。NodePortは特定のノードの特定のポート番号でサービスを公開するって機能なのですが、もし通信したい Pod がそのノード上で動いていない場合にも正常にリクエストを返すために他のノード上の Pod にリクエストをプロキシをします。
今回の構成ではノード2つでサービスを公開していてPodの数が1つなので、片方のノード上にはPodが動いて正常にリクエストを返せますが、もう片方のノードでは動いていないためそっちにリクエストが来た場合はもう片方のノードにプロキシします。
あとLBのhaproxyがラウンドロビンでリクエストを送るため、Pod の動いているノードとそうでないノードに交互にリクエストを送ってるためにログに交互に出てきてるんだと思います。
で、ここはNodePortで送信元IPを使う設定をすることができます。これを設定すると NodePort が nat をしなくなります。
1apiVersion: v1
2kind: Service
3metadata:
4 name: my-service
5 namespace: my-ns
6spec:
7 selector:
8 app: nginx
9 ports:
10 - port: 80
11 nodePort: 30080
12 type: NodePort
13 externalTrafficPolicy: Local
2. haproxyの設定
では、またコンテナのアクセスログを見てみましょう。
172.16.0.254 - - [31/Oct/2020:05:22:49 +0000] "GET /from_host01 HTTP/1.1" 404 153 "-" "curl/7.58.0" "-"
予想通りにLBのホストのIPアドレスがログに記録されるようになりましたね。
haproxy には送信元IPアドレスを渡す透過プロキシの設定があるのでそれを設定します。
14backend nodeport
15 mode tcp
16 balance roundrobin
17 source 0.0.0.0 usesrc clientip
18 server k8s1 172.16.0.11
19 server k8s2 172.16.0.12
これを設定しただけだと全リクエストがタイムアウトするようになります……
ぜんぜん解決策がわからかったので仕方無くtcpdumpでパケットを見ていたんですが、haproxy自体はちゃんとプロキシしてました。原因はコンテナ側からのarpリクエストが失敗しているせいっぽい感じでした。L7LBなんだから当然ですね……….
ちなみにこれはhaproxyのブログでちゃんと解説されてまして、この通りに設定するだけで動きました。
iptables -t mangle -N DIVERT
iptables -t mangle -A PREROUTING -p tcp -m socket -j DIVERT
iptables -t mangle -A DIVERT -j MARK --set-mark 1
iptables -t mangle -A DIVERT -j ACCEPT
ip rule add fwmark 1 lookup 100
ip route add local 0.0.0.0/0 dev lo table 100
iptables で該当するパケットにマークをつけて、haproxyに行くようにloopbackに転送するらしいです。
3. 1/2の確率でリクエストが失敗する….
ここまでの設定で送信元のIPアドレスがコンテナまで伝わるようになりました。
NetworkPolicyを適用するとちゃんと host01 は通信でき、 host02 はタイムアウトするという条件は達成できています。
ただ、 host01 からのリクエストでも 1/2 の確率でタイムアウトするという現象が発生してました3。
これは上の方でも紹介したNodePortで送信元IPを使うというドキュメントにちゃんと書いてあるんですが、送信元IPを使う設定をした場合はノード間のプロキシが行われなくなります4。
で、今回は片方には Pod があって片方には無いので、 Pod がある方にラウンドロビンされたらリクエストが成功して、もし無い方にリクエストが来た場合は NetworkPolicy 関係無くタイムアウトするって現象でした。
これを解決する方法はいくつかあるんですが、私はDeploymentの設定を雑にreplica: 2にして、あとはスケジュールの設定をして2つの Pod がノード間で分散するようにしました。
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: my-deployment
5 namespace: my-ns
6 labels:
7 app: nginx
8spec:
9 replicas: 2
10 selector:
11 matchLabels:
12 app: nginx
13 template:
14 metadata:
15 labels:
16 app: nginx
17 spec:
18 containers:
19 - name: nginx
20 image: nginx
21 ports:
22 - containerPort: 80
23 affinity:
24 podAntiAffinity:
25 requiredDuringSchedulingIgnoredDuringExecution:
26 - labelSelector:
27 matchExpressions:
28 - key: app
29 operator: In
30 values:
31 - nginx
32 topologyKey: kubernetes.io/hostname
k8sは基本的にはどのノードに Pod がデプロイされるかは制御できませんが、affinityという設定をすることで Pod やノードにつけたラベルを元にデプロイ先を制御することができます。
今回の設定は Pod 側に設定したラベルと同じラベルを持つ Pod が動いているノードにスケジュールしないって設定です、これを行うことでノード間で Pod を分散してデプロイさせることができるんですね。
これで 1/2 の確率でリクエストが失敗するって現象も無くなったので急いで解答として提出しました5。
追記
これは予選が終わってから気がついたのですが、私の意図していた通りだと Deployment のスケジュールの設定がrequiredDuringSchedulingIgnoredDuringExecutionではなくて preferredDuringSchedulingIgnoredDuringExecution なんですよね。
前者だとスケジュールの設定が守られなければ Pod がデプロイされなくて、後者だとスケジュールの設定は優先するけど該当するノードが無い場合はスケジュールは無視されて普通にデプロイされます6。
まとめ
以上ICTSC2020予選のwriteupでした。なにか理解不足や間違いがあるかもしれません。見つけたらご連絡下さい。
個人的な感想で言えば、コンテナとかk8s辺りの私の得意とする領域を一人でやってしまったので、後輩の育成のためを思えばもうちょっとチーム内の問題配分を考えるべきだったかなとか思いますが、まあ、後輩は優秀なので私が卒業する来年以降も自力でなんとかしてくれるでしょう。
なお運営による解説がもう出ていますし、当日使っていたgithubのissueをpublicにしたので誰でも見れます。良かったらどうぞ。